「正規表現」を利用すると複雑な文字列から任意の部分を抽出したり置き換えたりすることができます。
ここでは、例として「さくらインターネット リソース情報自動報告プログラム(PHP 版)(Ver.0.26)」以前のデータを手動でファイルに蓄積していた場合、今後自動的に作成されるファイルに小さな差異が生じるので、これを解決するために正規表現を利用します。
スポンサードリンク
上記は、得られる情報を単純にカンマ区切りにしたデータを手動で蓄積されたもので、日付も以下のようになっています。
xxx,YYYY/MM/DD hh:mm:ss,xxx
上記の状態でもエクセルなどで開けば正しく表示されますが、どうやら正しいCSVフォーマットではないらしいようです。
CSV で書き出す際にPHP の機能を利用して出力したところ、日付がダブルクォートで囲まれ以下のようになっていました。
xxx,"YYYY/MM/DD hh:mm:ss",xxx
おそらく混在していてもそれらのソフトウェアは正しく処理できると思いますが、混在しているのは気分のよいものではありません。しかし、修正するとしても数行なら手作業でも良いけれど、複数のファイルにまたがって膨大なデータを間違えずに書き換えるのは避けたいところ。
そこで登場するのが正規表現です。
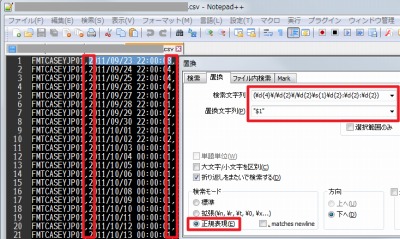
既存のファイルから「YYYY/MM/DD hh:mm:ss」の部分を探し出し、ダブルクォートを付ければ、今後自動的に書き込まれるデータとの差異がなくなります。これらの作業は、正規表現に対応したエディタソフトを利用すると簡単にできます:
検索する文字列に以下を指定し、置き換える文字列として「”$1″」とします。
(\d{4}\/\d{2}\/\d{2}\s{1}\d{2}:\d{2}:\d{2})
検索する文字列は日付を見つける正規表現で、置き換える文字列の$1 は一致した部分を表します。従って、「”$1″」は、一致した部分(=日付)をダブルクォートで囲むという置き換えを行なっています。
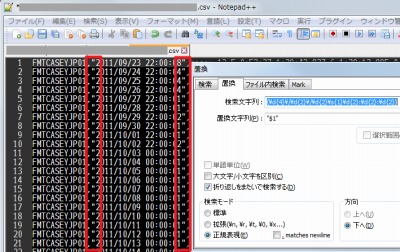
上の画像は処理された例です。
ちなみに正規表現では、同じ物を表現するのにいくつもの表現があります。上の例は、文字通りひとつの例に過ぎません。
今回のデータは数値などがたくさんあるので、間違った部分に合致しないように、どちらかと言うと厳格な表現になっているかもしれませんが、単純に表現するなら以下でも良いはずです(テストしたところ正しく動作した)。
([0-9 \/:]{19})
–
コメント